Building a Fly.io-like Scheduler Part 2: Resource Requirements and Multi-Region

In our the last post, we built a simple coordinator and a worker that could increment a number from a client request. That simple example introduced us to scheduling tasks on workers from a compute cluster in the same style that fly.io uses to schedule machines on their compute nodes.
But our example was really simple, workers were only available or unavailable based on whether they were already executing a task. In reality workers would have more constraints to consider like available resources (CPU, Memory, GPU, Disk), locality (cloud region), and architecture (arm, x86).
In this post, we’ll build on our previous coordinator and worker to support specifying workload locality, and how many “slots” (arbitrary compute unit) a task takes. Workers will then only be able to schedule workloads if they meet all requested conditions for an incoming scheduling request.
All code can be found on Github.
Understanding requirements
When our coordinator broadcasts a task scheduling request, we’ll now include some requirements:
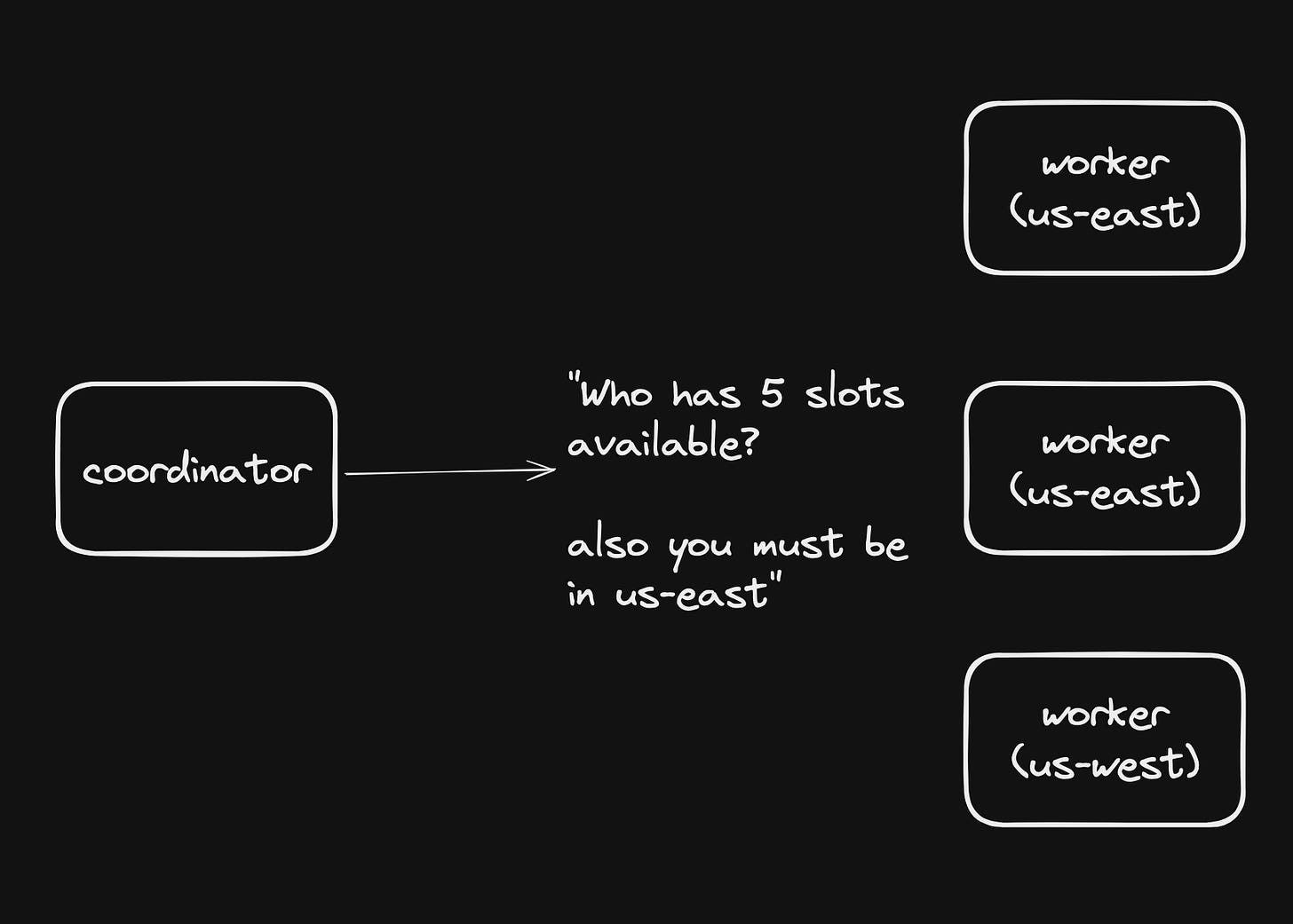
Workers comparse these requirements and respond if they can fulfill the request:
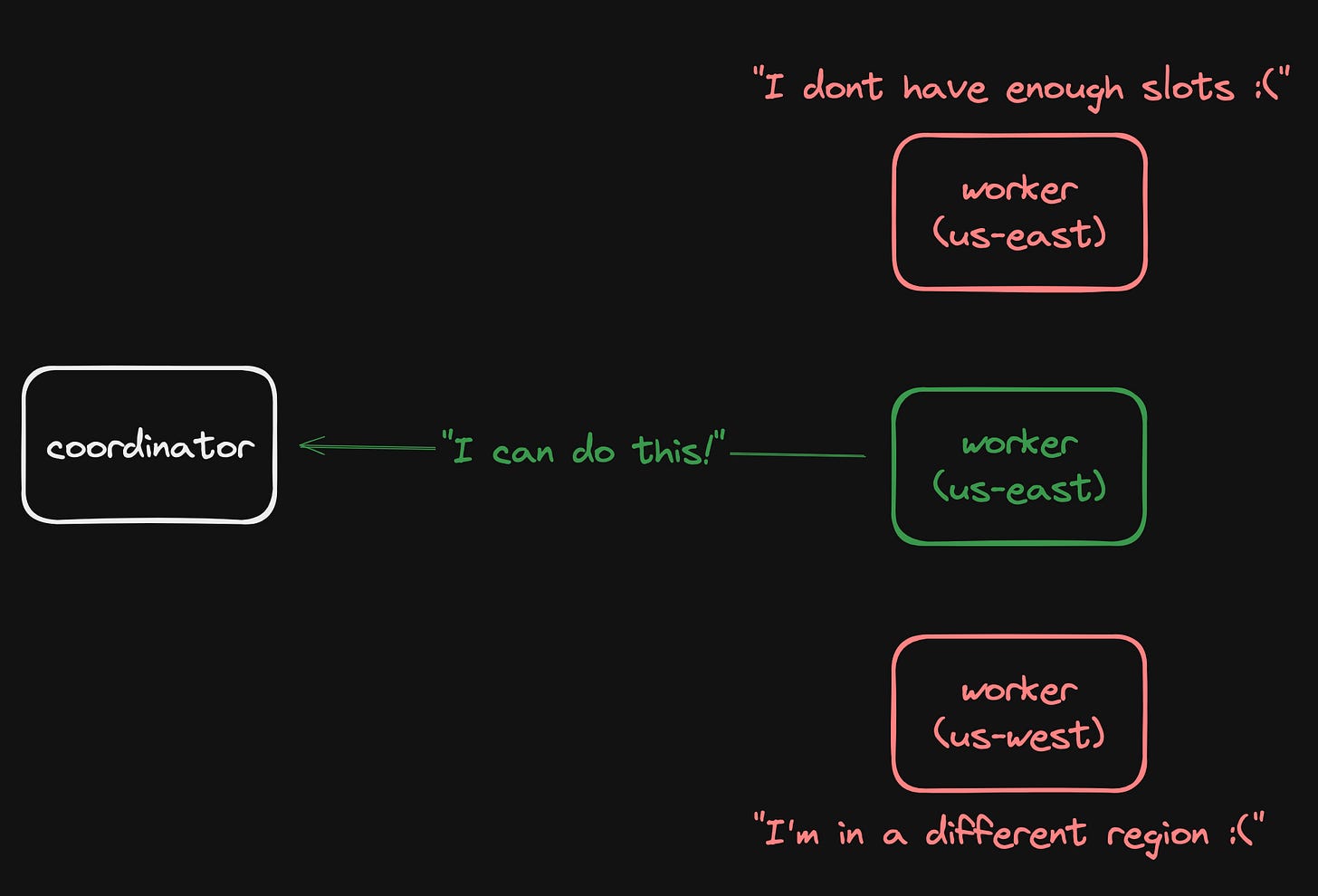
When a worker node can’t fulfill a request, it just ignores it.
This allows us to send out scheduling requests that meet our criteria, either from the client themselves, or our own.
Adding task requirements
The first thing we need to do is add support for different kinds of requirements: Region and Slots as mentioned before.
type (
Requirements struct {
Region string
// Arbitrary compute unit
Slots int64 `validate:"required,gte=1"`
}
ScheduleRequest struct {
RequestID string
Task string
Requirements Requirements
}
)The coordinator will be aware of all possible requirements, so they can be validated and have any defaults set.
Worker nodes will handle only known resource requirements, and if they come across a requirement they don’t know about, they immediately determine they can’t fulfill the request.
That will enable us to add new requirements in the future, like GPU and architecture, without having to update all workers.
Our previous code already included the requirements in the scheduling request emitted to workers, so now we need to add support for the requirements.
We’ll add some support for new worker configuration options:
var (
REGION = os.Getenv("REGION")
SLOTS = GetEnvOrDefaultInt("SLOTS", 10)
)Then, when handling a scheduling request on the worker, we can add support for keeping track of the current number of available slots, and checking we if we fulfill a scheduling request.
We start by keeping track of resources, and make sure we are able to release them:
func startWorkerNode(nc *nats.Conn) {
logger.Debug().Msgf("starting worker node %s with slots %d", utils.WORKER_ID, utils.SLOTS)
availableSlots := atomic.NewInt64(utils.SLOTS)
// We need a sync map to track reservations
reservations := sync.Map{}
releaseResources := func(requestID string) {
slots, found := reservations.LoadAndDelete(requestID)
if !found {
// We didn't even have it, ignore
return
}
availableSlots.Add(slots.(int64))
logger.Debug().Msgf("worker %s released resources", utils.WORKER_ID)
}We then check to make sure that our region matches the region of the request. We’ll also allow a request that doesn’t specify a region to be answered by any node:
// Scheduling loop
_, err := nc.Subscribe("scheduling.request.*", func(msg *nats.Msg) {
logger.Debug().Msgf("Worker %s got scheduling request, reserving resources", utils.WORKER_ID)
var request scheduling.ScheduleRequest
utils.JSONMustUnmarshal(msg.Data, &request)
// Check whether the region matches (if provided)
if request.Requirements.Region != "" && request.Requirements.Region != utils.REGION {
logger.Debug().Msgf(
"worker %s cannot fulfill request, different region",
utils.WORKER_ID,
)
return
}
// Check whether we have enough available slots
if request.Requirements.Slots > availableSlots.Load() {
logger.Debug().Msgf(
"worker %s cannot fulfill request, not enough slots",
utils.WORKER_ID,
)
return
}
// Reserve the slots
// Note: would need better handling to protect against going negative in prod
availableSlots.Sub(request.Requirements.Slots)
reservations.Store(request.RequestID, request.Requirements.Slots)If we match a region, and have enough slots, we’ll then respond that are able to take the task as usual.
We’ll also release the resource reservations when we get a release message, but now we check the request ID from the reservations map:
// Release loop
_, err = nc.Subscribe("scheduling.release", func(msg *nats.Msg) {
var payload scheduling.ReleaseResourcesMessage
utils.JSONMustUnmarshal(msg.Data, &payload)
if payload.ExemptWorker == utils.WORKER_ID {
// We are exempt from this
return
}
releaseResources(payload.RequestID)
logger.Debug().Msgf("Worker %s releasing resources", utils.WORKER_ID)
})We’ll also release them when we complete a task:
_, err = nc.Subscribe(fmt.Sprintf("scheduling.reserve_task.%s", utils.WORKER_ID), func(msg *nats.Msg) {
// Listen for our own reservations
// ... code
// we are done, we can release resources
releaseResources(reservation.RequestID)
})Testing our new requirements
We can simply define our two workers to be in two different virtual regions, but since incrementing a number is so fast we’ll have a hard time simulating unavailable slots between requests.
To solve this, we’ll add a `SleepSec` property to our payload, and if that exists we’ll sleep for that many seconds before completing the task:
if sleepSec, ok := reservation.Payload["SleepSec"].(float64); ok {
logger.Debug().Msgf(
"worker %s sleeping for %f seconds",
utils.WORKER_ID,
sleepSec,
)
time.Sleep(time.Second * time.Duration(sleepSec))
}Now, we can try it out!
After getting NATs running again with
docker-compose up -dwe’ll get our coordinator running in one terminal:
go run . coordinatorAnd in another two terminals, start two workers in different regions (we’ll leave the default 10 slots)
WORKER_ID=a REGION=us-east go run . workerWORKER_ID=b REGION=us-west go run . workerThen, we can submit a request to schedule:
curl -d '{
"Task": "increment",
"Payload": {
"Num": 1
},
"Requirements": {
"Slots": 5
}
}' -H 'Content-Type: application/json' http://localhost:8080/scheduleJust as before, this randomly selects a node and schedules on it:
> Worker b got scheduling request, reserving resources
> Got reservation on worker node b with payload {Task:increment Payload:map[Num:1] RequestID:123b6d38-1e44-4dd2-8465-371b3a3222db}We can now add a region requirement to the request to see that it now only ever gets scheduled on a specific node:
curl -d '{
"Task": "increment",
"Payload": {
"Num": 1
},
"Requirements": {
"Slots": 5,
"Region": "us-east"
}
}' -H 'Content-Type: application/json' http://localhost:8080/scheduleNo matter what, worker b will never schedule this request:
> Worker b got scheduling request, reserving resources
> worker b cannot fulfill request, different regionAnd worker a will always get it:
> Worker a got scheduling request, reserving resources
> Got reservation on worker node a with payload {Task
94-cd738a1ceaad}
# task completion
> worker a released resourcesTo test running out of slots, we can increase the slots requirement, and add a sleep:
curl -d '{
"Task": "increment",
"Payload": {
"Num": 1,
"SleepSec": 4
},
"Requirements": {
"Slots": 8,
"Region": "us-east"
}
}' -H 'Content-Type: application/json' http://localhost:8080/schedule> Worker a got scheduling request, reserving resources
> worker a sleeping for 4.000000 seconds
# another request:
> Worker a got scheduling request, reserving resources
> worker a cannot fulfill request, not enough slotsIf we take out the region requirement, we can see that the second request will now schedule on the other node:
> Worker a got scheduling request, reserving resources
> worker a sleeping for 4.000000 seconds
# another request:
> Worker b got scheduling request, reserving resources
> worker b sleeping for 4.000000 secondsWe’ve now successfully added requirements to our tasks so that they can only schedule in specific regions, and when enough resources (Slots) are available on a given node.
This system can be extended to many more kinds of requirements, a short list could be:
- CPU arch (x86 vs arm)
- GPU support (for AI inference scheduling)
- Available CPU, Memory, or Disk
- Physical hardware (a robot in a factory, a drone, IoT device)
I also emphasize that there is a lot of “production readiness” missing from this system, and this guide is just to serve as a reference. A few things that are missing:
- Timeouts for temporary resource reservations (e.g. what happens if we never get a release?)
- Proper error handling
- Proper draining and unsubscribing of topics
That wraps up this post series for now!
Maybe I’ll add a third part in the future extending the functionality even further, or build some projects off this concept (like extending StableInterfaces to run on these kinds of hosts for a better DX).
Here are some more resources if you’re curious:
- The Github repo for this post series
- Plane.dev - a sort of open source fly.io on your own infrastructure, using similar scheduling techniques
- The original fly.io artcile on their scheduler
Discuss this post!
Check out this post on HackerNews and Lobste.rs!