Building a Fly.io-like Scheduler Part 1: Basic Coordinator and Workers

Fly.io has built a very cool platform, allowing for super quick allocation and destruction of compute. That’s extremely useful in many use cases like serverless functions, background job execution, and more.
In this post series, we’ll build our own basic compute scheduler that can be used for anything from serverless functions, AI inference, SQL queries, and more!
All code from this post is available on Github.
Scheduling: sync vs. async
A distinct difference between fly and other schedulers such as Kubernetes is that they do scheduling synchronously: You either get the machine when you ask for it, or you don’t and get an error. There’s no pending state with fly, which simplifies workloads like holding requests while a serverless function cold-boots.
They have a great blog post about building this new scheduler which dives into a lot of the details, but of course, it’s very specific to their architecture.
The beauty of this scheduling model, besides being able to synchronously scheduling workloads, is that the workers are the source of truth for their availability. There’s no worrying about desync from a database on what resources a worker has available (in fact we don’t even use a DB to build this!), and nodes can just join and leave the cluster as they wish.
As mentioned in the above post, building a scheduler can be very simple, or very complex, depending on the requirements. We’ll start super simple, and add more functionality in subsequent posts
How the scheduler works
Let’s first describe how the scheduler will work.
The scheduler performs a simple flow to find a worker node:
- Coordinator gets a scheduling request (with some constraint like location, available resources, etc.)

Using a similar analogy as the fly article, you can think of this like a customer going to a broker seeking to buy something.
- Coordinator broadcasts a request for a worker node that can fulfill the requirements
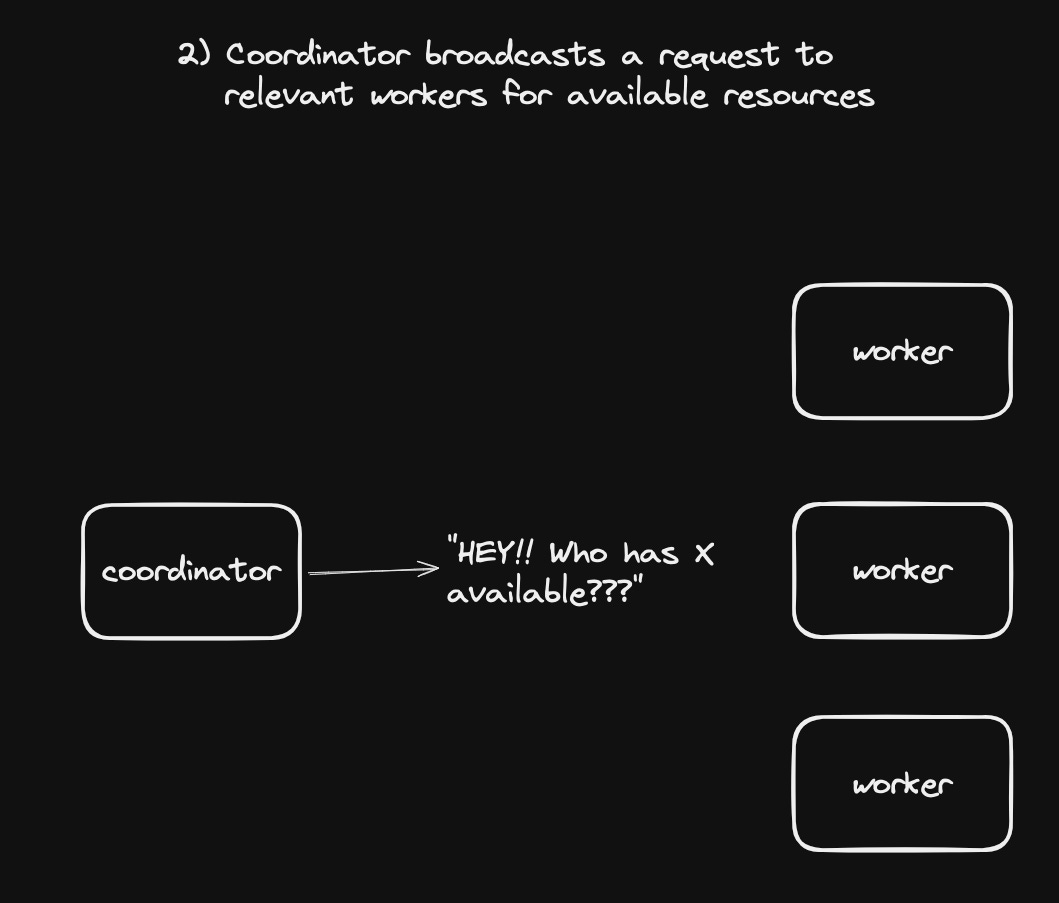
This is like the broker now going to direct providers, and getting bids for a contract, with the “best deal” being the node that responds first.
Like fly, and to support polyglot workers, we’ll use NATS request-reply to handle broadcasting and getting the first response.
- All workers nodes that can fulfill the requirements respond
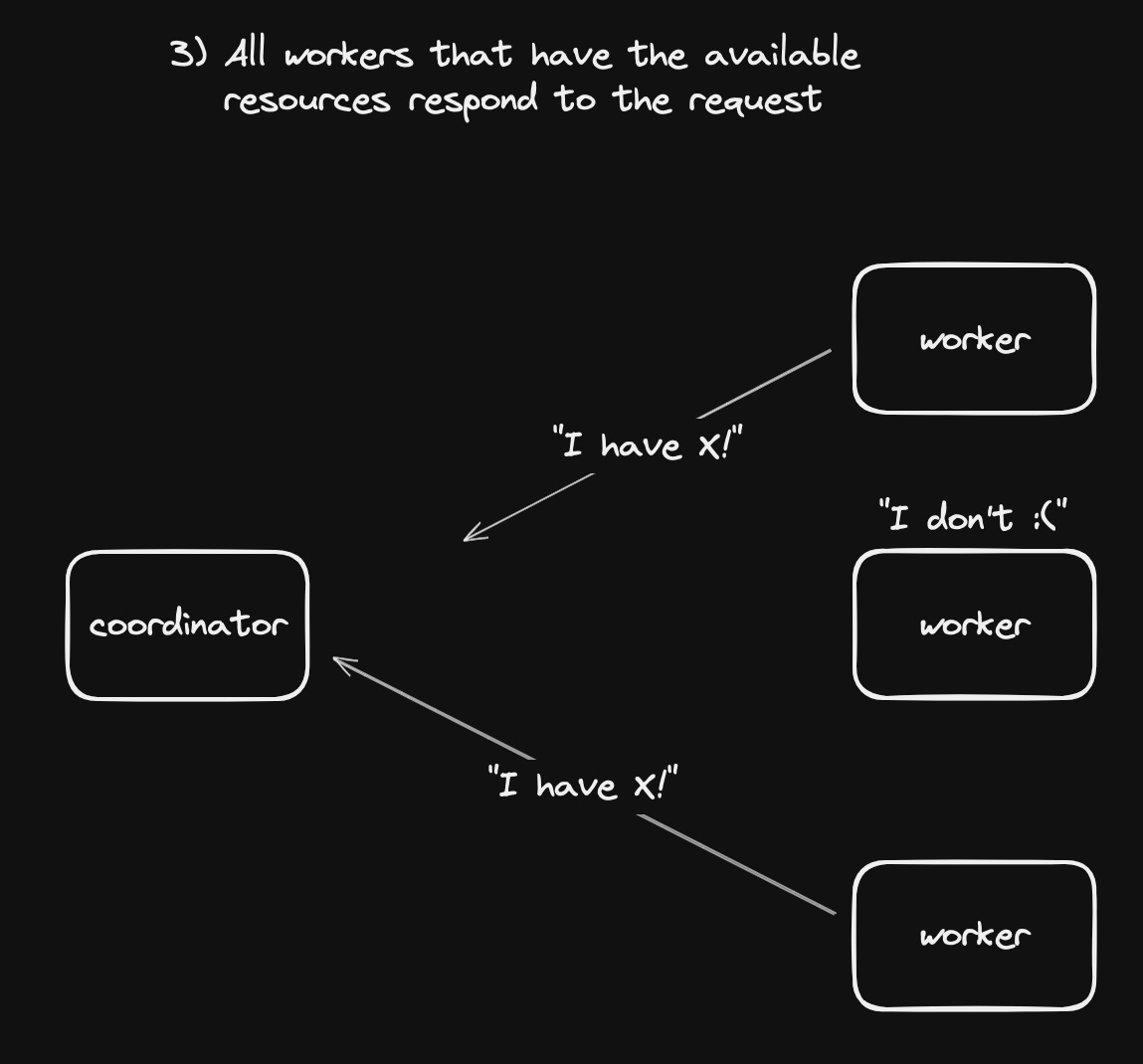
This is like providers submitting bids for the contract.
Typically, the workers will briefly hold a reservation for the resources, say for 5 seconds, to make sure that if they are selected by this request another request hasn’t already claimed those resources.
- The coordinator uses the first response, and schedules some workload on the selected worker node
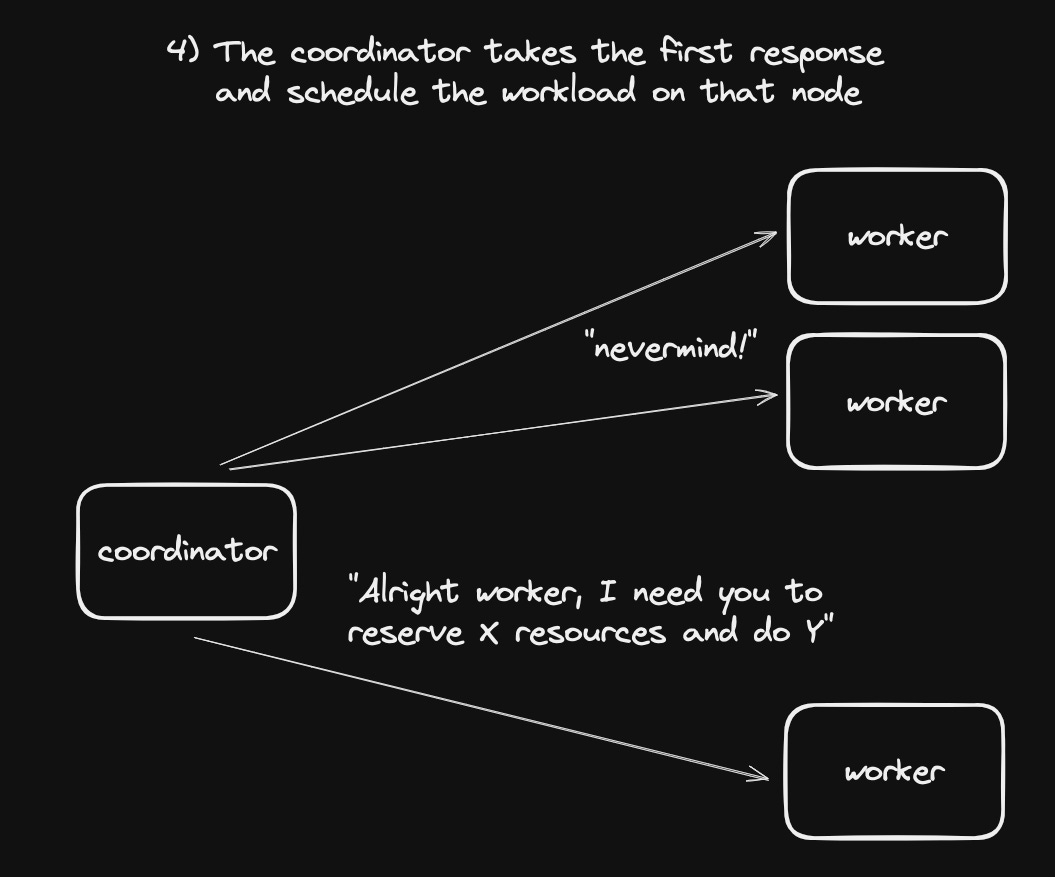
The coordinator can also send out a cancel message for a specific request, which will tell the worker nodes to free their temporarily reserved resources.
- The worker completes the task, and tells the coordinator
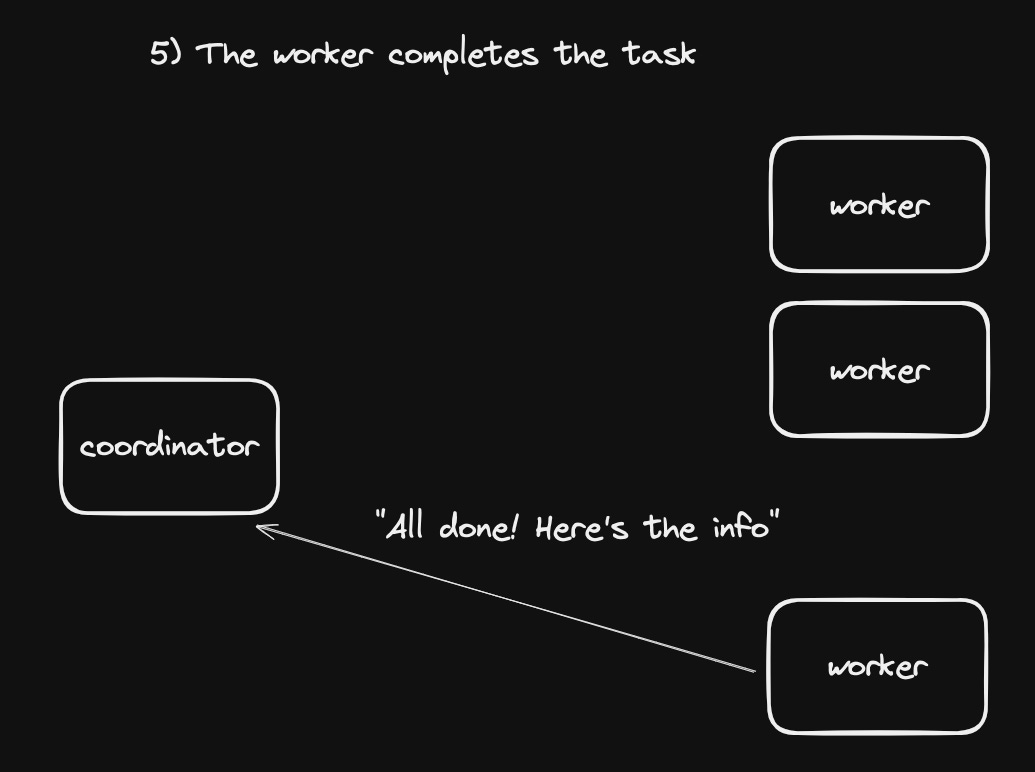
- Finally, the coordinator returns to the client what it needs to know:

In the case of fly, you’ve now scheduled a machine, but in our world this could be anything:
- Docker container
- Serverless function invocation
- SQL query
- AI inference
- anything, really!
We can additionally put limitations on our request for resources, like a specific set of regions, nodes that have GPUs, nodes that are have ARM CPUs, nodes with 1vCPU and 2GB of memory available to reserve, what ever we want :)
Set up NATS
Now that we know how the scheduler needs to work, let’s set up the one dependency we will need, NATS, which will handle the messaging between coordinator nodes and worker nodes.
NATS has great multi-language support, and native clustering for both regional and multi-region clusters, meaning if we scaled out we could have one logical NATS cluster for everything.
We’ll create just a single node with docker compose for now:
version: "3.7"
services:
nats:
image: nats
ports:
- "8222:8222"
- "4222:4222"
command: "--cluster_name NATS --cluster nats://0.0.0.0:6222 --http_port 8222"Building the coordinator
With NATS set up, we can dive into building the coordinator.
(Code at http_server/schedule.go)
To keep it simple, we’ll make an HTTP server with an endpoint for invoking workloads. My language of choice is Go, so we’ll build in that.
We will build an endpoint that will take a request from a client, execute the task on a worker node, and return the response.
The first thing we need to do is validate the incoming request, and ask for available worker nodes:
var body PostScheduleRequest
if err := ValidateRequest(c, &body); err != nil {
return c.String(http.StatusBadRequest, err.Error())
}
// Request resources from workers
logger.Debug().Msgf("Asking workers to schedule '%s'", body.Task)
msg, err := s.NatsClient.Request(fmt.Sprintf("scheduling.request.%s", body.Task), utils.JSONMustMarshal(scheduling.ScheduleRequest{
RequestID: c.RequestID, // use the unique request ID
Task: body.Task,
Requirements: body.Requirements,
}), time.Second*5)Next, we can reserve the worker that responded first, and release other worker nodes:
var workerRes scheduling.ScheduleResponse
utils.JSONMustUnmarshal(msg.Data, &workerRes)
logger.Debug().Msgf("Worker %s responded to schedule request", workerRes.WorkerID)
// tell other workers to release resources
s.mustEmitRelease(c.RequestID, workerRes.WorkerID)
// Tell the worker that they are reserved, and to do the task
msg, err = s.NatsClient.Request(fmt.Sprintf("scheduling.reserve_task.%s", workerRes.WorkerID), utils.JSONMustMarshal(scheduling.ReserveRequest{
Task: body.Task,
Payload: body.Payload,
}), time.Second*5)mustEmitRelease just tells all workers except the workerRes.WorkerID to release their temporary resource reservation so they can accept new tasks.
Finally, we can respond to the client with the output of the worker node task execution:
var reserveRes scheduling.ReserveResponse
utils.JSONMustUnmarshal(msg.Data, &reserveRes)
if reserveRes.Error != nil {
c.String(http.StatusInternalServerError, *reserveRes.Error)
}
return c.JSON(http.StatusOK, reserveRes.Payload)At this point, we have our coordinator reserving resources on a worker node, executing a task, and returning the result to the client.
Building a basic worker
We have the coordinator ready, but we need to make the worker nodes to actually respond to requests and task executions, so we’ll build a simple worker node that can increment a number.
In main.go, we’ll have different entrypoints based on whether the first argument is worker or coordinator.
(Code at main.go)
Within the worker entrypoint, we first want to listen for scheduling requests:
available := atomic.NewBool(true) // because different goroutines will be accessing
// Scheduling loop
_, err := nc.Subscribe("scheduling.request.*", func(msg *nats.Msg) {
logger.Debug().Msgf("Worker %s got scheduling request, reserving resources", utils.WORKER_ID)
// At the moment we don't care about resources, so we just reserve
if !available.Load() {
// just ignore
return
}
available.Store(false)
err := msg.Respond(utils.JSONMustMarshal(scheduling.ScheduleResponse{
WorkerID: utils.WORKER_ID,
}))
if err != nil {
logger.Fatal().Err(err).Msg("failed to respond to resource request message")
}
})We also need to listen for resources releases (when we aren’t the first responder):
// Release loop
_, err = nc.Subscribe("scheduling.release", func(msg *nats.Msg) {
var payload scheduling.ReleaseResourcesMessage
utils.JSONMustUnmarshal(msg.Data, &payload)
if payload.ExemptWorker == utils.WORKER_ID {
// We are exempt from this
return
}
available.Store(true)
logger.Debug().Msgf("Worker %s releasing resources", utils.WORKER_ID)
})And finally, when we are reserved, we need to execute the task:
_, err = nc.Subscribe(fmt.Sprintf("scheduling.reserve_task.%s", utils.WORKER_ID), func(msg *nats.Msg) {
// Listen for our own reservations
var reservation scheduling.ReserveRequest
utils.JSONMustUnmarshal(msg.Data, &reservation)
logger.Debug().Msgf("Got reservation on worker node %s with payload %+v", utils.WORKER_ID, reservation)
err = msg.Respond(utils.JSONMustMarshal(scheduling.ReserveResponse{
Error: nil,
Payload: map[string]any{ // float64 because of JSON
"Num": reservation.Payload["Num"].(float64) + 1,
},
}))
if err != nil {
logger.Fatal().Err(err).Msg("failed to respond to reservation request")
}
available.Store(true) // we are done, we can release resources
})Now we are ready to try scheduling some tasks!
Testing with a client
After running docker compose up -d to get NATS running, in one terminal, we can start the coordinator:
go run . coordinatorIn two more terminals, we can start two worker nodes:
WORKER_ID=a go run . workerWORKER_ID=b go run . workerFinally, from a fourth terminal, we can make a request to the coodinator to increment our number:
curl -d '{"Task": "increment", "Payload": {"Num": 1}}' -H 'Content-Type: application/json' http://localhost:8080/scheduleWe get the data back from the coordinator:
{"Num":2}Our number was incremented!
Obviously incrementing a number is trivial, but imagine this being AI inference output, a SQL query result, or connection info for a container instance! The possibilites are immense with this foundation :D
In the terminal for worker a, we can see it was the chosen worker node:
> Worker a got scheduling request, reserving resources
> Got reservation on worker node a with payload {Task:increment Payload:map[Num:1]}In the worker `b` terminal, we can see it was not chosen, and resources released:
> Worker b got scheduling request, reserving resources
> Worker b releasing resourcesIf we run the curl command a few more times, we can see worker b gets chosen occasionally:
> Worker b got scheduling request, reserving resources
> Got reservation on worker node b with payload {Task...Success! We can now add as many workers as we like as well to increment numbers :)
Keep in mind there is a lot missing from these workers, like reservation timeouts, ensuring reservations are a previously known request (id), and proper error handling. You can also totally run multiple coordinator processes as well.
Stay tuned for Part 2: Resource Requirements and Regional Workloads
Worker availability was as simple as could be in this post: it either was available, or it wasn’t because it was already executing something.
In the next post, we’ll put some more resource limitations on the worker nodes so that scheduling requests can only apply to specific worker nodes based on their capabilities (e.g. available CPU or memory) and locality (e.g. what cloud region).
This means with one logical cluster you can have different workers that can:
- Run a docker container
- Invoke a JS serverless function
- Run AI inference
- Manage persistent services (VM, stateful object, etc.)
- Talk to physically connected hardware
Subscribe to get notified!